Load balancing is one of the typical features of messaging systems. Although some don't do it (MQTT), most of them provide some way to spread a workload among cluster of boxes.
In ZeroMQ load balancing is done via REQ (requests that require replies) or, alternatively, by PUSH socket (requests that don't require replies). When designing it, I've opted for completely fair load-balancer. What it means is that if there are two peers able to process requests, first request goes to the first one, second request goes to the second one, third request goes ot the first one again etc. It's called round-robin load balancing. Of course, if a peer is dead, or it is busy at the moment, it's removed from the set of eligible destinations and left alone to re-start or finish the task it is dealing with.
For nanomsg I've chosen a more nuanced approach. Similar to ZeroMQ, load balancing is done by REQ and PUSH sockets, however the algorithm is different. Instead of having a single ring of peers eligible for processing messages, nanomsg has 16 such rings with different priorities. If there are any peers with priority 1, messages are round-robined among them. The peers with priorities from 2 to 16 get no messages. Only after all the priority 1 peers are dead, disconnected or busy load balancer considers peers with priority 2. Once again, requests are round-robined among all such peers. If there are no more peers with priority 2, priority 3 peers are checked etc. Of course, once a peer with priority 1 comes back online, any subsequent messages will be sent to it instead of to the lower priority peers.
Now, the obvious question is: How is this useful? What can I do with it?
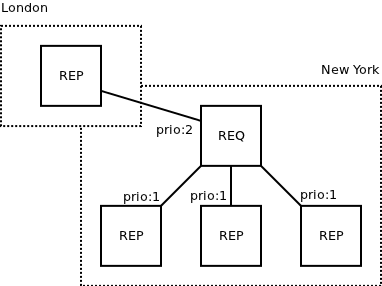
Basically, it's a failover mechanism. Imagine you have two datacenters. One in New York, other one in London. You have some boxes able to provide specific kind of service. There are some of them on either site. You want to avoid trans-continental traffic and the associated latency. However, if things go bad and there's no service available on your side of the ocean you may prefer the trans-Atlantic communication to not being able to use the service at all. So, this is a configuration you can set up in New York:
As you can see, local services have priority 1 and they are thus used, unless all of them are dead, busy or disconnected. Only at that point the requests will begin to be router across the ocean.
Here's the code needed to set up the requester:
int req;
int sndprio;
char buf [64];
/* Open a REQ socket. */
nn_init ();
req = nn_socket (AF_SP, NN_REQ);
/* Connect to 3 servers in New York and 1 in London. */
sndprio = 1;
nn_setsockopt (req, NN_SOL_SOCKET, NN_SNDPRIO, &sndprio, sizeof (int));
nn_connect (req, "tcp://newyorksrv001");
nn_connect (req, "tcp://newyorksrv002");
nn_connect (req, "tcp://newyorksrv003");
sndprio = 2;
nn_setsockopt (req, NN_SOL_SOCKET, NN_SNDPRIO, &sndprio, sizeof (int));
nn_connect (req, "tcp://londonsrv001");
/* Do your work. */
while (1) {
nn_send (req, "MyRequest", 9, 0);
nn_recv (req, buf, sizeof (buf), 0);
process_reply (buf);
}
/* Clean up. */
nn_close (req);
nn_term ();
So far so good. Now let's have a look at more sophisticated setup:
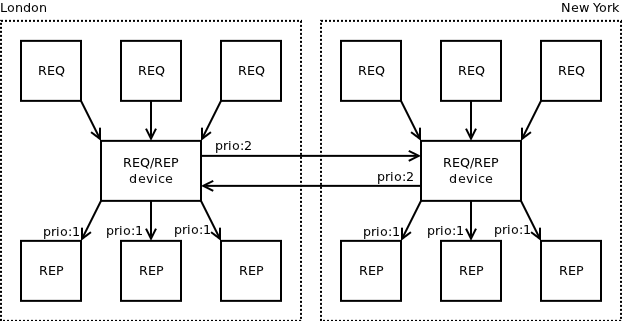
As can be seen, there's a cluster or workers (REPs) on each site. Clients (REQs) access the cluster via an intermediate message broker (REQ/REP device). The broker at each site is set up in such a way that if none of the boxes in local cluster can process the request, it is forwarded to the remote site. Of course, if there's no worker available on either site, the messages would bounce between New York and London, which is something you probably don't want to happen and you should take care to drop such messages in the broker. (Alternatively, if you believe that loop detection is a problem worth addressing in nanomsg itself, feel free to discuss in on nanomsg mailing list.)
There's a similar priority system implemented for incoming messages (NN_RCVPRIO option). It's somehow less useful than the load-balancing priorities, however, it may prove useful in some situations. What it allows you to do is to process requests from one source in preference to requests from another source. Of course, this mechanism kicks in only if there is a clash between the two. In slow and low-collision systems the inbound priorities have little effect.
Let's have a look at the following setup:
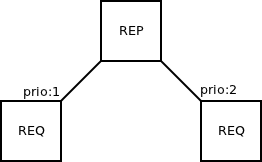
As long as there are requests from the client (REQ) on the left, the server (REP) will process them and won't care about requests from the client on the right.
EDIT: The RCVPRIO option was removed from nanomsg for now, as there were no obvious use cases for it. If you feel like needing it, please discuss your use case on nanomsg mailing list.
Finally, it's interesting to compare the above system with how priorities are dealt with in traditional messaging systems. Old-school messaging systems typically attach the priority to the message. The idea is that messages with high priorities should be delivered and processed faster than messages with low priorities.
nanomsg, on the other hand, believes that all messages are created equal — there's no priority attached to a message and instead it's paths within the topology that can be prioritised. In other words, nanomsg believes in clear separation of mechanism (sending/receiving messages) and policy (how and with what priority are the messages routed). In yet another words, there's a clear separation of "programmer" role (sending and receiving messages) and "admin" role (setting up the topology, with all the devices, priorities etc.)
While the above may seem to be just a matter of different design philosophy, there are sane reasons why nanomsg handles the priorities in the way it does.
Traditional broker-based messaging system stores messages inside of the broker. Typically, the priorities are implemented by having separate internal message queues for different priority levels. The sender application sends a message via TCP to the broker where it is stored in appropriate queue (depending on the priority level defined in the message). The receiver application asks for a message and broker retrieves a message from the highest-priority non-empty queue available and sends it back via TCP:
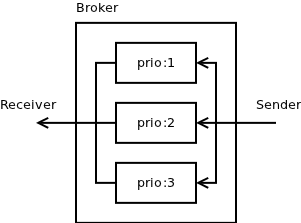
This model works OK for traditional, slow messaging systems. The messages spend most of their lifetime stored in prioritised queues on the broker so there's no problem. However, in modern, fast, low-latency and real-time systems it is no longer the case. The time spent inside of broker approaches zero and most of the message lifetime is spent inside TCP buffers.
That changes the situation dramatically. TCP buffer is not prioritised, it's a plain first-in-first-out queue. If a high-priority message is stuck behind a low-priority message, bad luck, the low priority message is going to be delivered first:
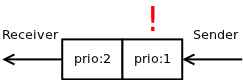
To solve this problem nanomsg offers an alternative solution: Create different messaging topologies for different priorities. That way there are multiple TCP connections involved and head-of-line-blocking problem, as described above, simply doesn't happen:
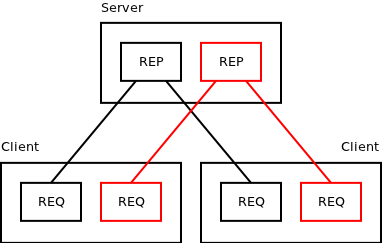
Topology for "urgent" messages is drawn in red. Topology for "normal" messages is in black. Client sends request to either "urgent" or "normal" REQ socket, depending on the priority level it is interested in. Server polls on both REP sockets and processes messages from the "urgent" one first. Finally, given that the two topologies use two different TCP ports, it is possible to configure network switches and routers is such a way that they treat urgent messages in preference and that they allocate certain amount of bandwidth for them, so that network congestion caused by normal messages won't effect delivery of urgent messages.
Jan 28th, 2013