
I've already wrote about "survey" scalability protocol in this blog. The article explained how the survey protocol can be used to collect information from a set of computers. This article, on the other hand, shows how to use "survey" protocol to combine high reliability with low latency.
First, let's have a look how REQ/REP protocol handles reliability. The basic idea is that there are multiple instances of the service, so if one of them fails, others are still available for processing requests. The only problem with this approach is that if a service instance crashes while processing a request it will never produce a reply and client will wait for it forever. To handle this situation REQ/REP protocol has the NN_REQ_RESEND_IVL socket option, set by default to 60 seconds. If reply is not received within this time window, client socket (REQ) will assume that the service instance processing the request have crashed or became in some other way unavailable and re-sends the request. It will now be routed to a different service instance which will process the request and deliver the reply to the client. Check the sequence of events on the following diagram:
That kind of of approach works well, but it has one drawnback that may or may not be a problem, depending on the application needs. If the service instance crashes, reply is delayed by 60 seconds. You can of course decrease the resend interval (NN_REQ_RESEND_IVL socket option) to, say, 1 second, or even lower, however, then you are in risk of processing redundant requests:
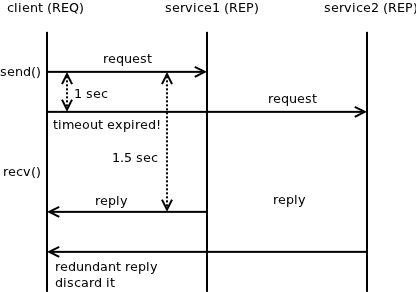
As can be seen on the diagram above, if the resend interval is set to 1 second, but processing the request takes 1.5 second, additional request is generated and the reply is silently dropped.
Thus, we are getting the worst of the possible worlds: We have to process each request multiple times, but we still have a 1 second latency overhead in the case one service instance fails.
The ideal solution would be to send two requests immediately. Then get the first reply and ignore the second. The system would be reliable — if one service instance fails, other one would still handle client requests — and at the same time there would be no latency impact in the case of failure:

So, in theory we could add a new socket option to nanomsg, specifying how many copies of the request should be sent immediately. The user could set such option to say 3. If there were 10 instances of the service, the request would be sent to 3 of them and the first reply will be returned to the user. Subsequent replies will be silently dropped.
However, the problem with this solution is that REQ/REP protocol is supposed to scale upwards and downwards by adding or removing instances of the service. Now imagine what would happen if you removed 9 instances of the service from your 10 instance computing cluster. There will remain only a single instance of the service and given that REQ socket load balances requests, all 3 copies of the request will be routed to the same instance! In other words, the request will be processed three times on the same box with no added benefit.
As can be seen REQ/REP protocol doesn't work very well once you want to use nanomsg for active-active reliability.
Luckily, "survey" pattern has exactly the behaviour we are looking for. It sends the request to all the connected service instances. That guarantees not only that the request will be processed in redundant manner to provide reliability with zero latency impact, but also that the same request won't be sent to the same sevice instance twice, thus avoiding useless overhead. When receiving the responses, unlike with REQ/REP pattern, you can receive all of them, rather than just a single one. However, if you just send the next request after receiving the first reply, all the pending replies for the old request will be silently dropped:
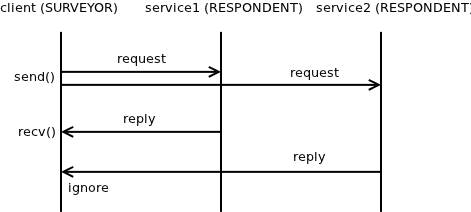
March 22nd, 2013